When you're building conversational commerce, every millisecond of latency and every cent of inference cost compounds. We needed a model that could instantly understand whether a product is what a shopper is actually looking for — and we needed it to be fast, cheap, and accurate.
So we fine-tuned our own. Then we benchmarked it against every major frontier LLM. The results surprised us.
The Problem: Product-Query Relevance at Scale
At the core of any AI shopping assistant is a deceptively hard question: "Is this product actually what the customer wants?"
This isn't binary. A customer searching for "waterproof hiking boots" might encounter:
- Exact match: Waterproof hiking boots in their size — perfect.
- Substitute: Water-resistant trail runners — not exactly what they asked for, but functional.
- Complement: Waterproofing spray — doesn't fulfill the query, but pairs well with the answer.
- Irrelevant: A hiking backpack — related topic, wrong product entirely.
Getting this classification wrong doesn't just hurt relevance — it erodes trust. Recommend an irrelevant product and the shopper leaves. Miss a good substitute and you lose a sale.
Our Approach: Fine-Tuned DistilBERT
Instead of routing every classification through an LLM API, we fine-tuned DistilBERT (66M parameters) on a blend of three data sources — public datasets, synthetic examples, and manually labeled proprietary data.
Training Data: Three Sources, One Dataset
Getting high-quality labeled data for e-commerce classification is hard. No single source gives you enough coverage, so we combined three:
- Public datasets: The ECInstruct Multi-class Product Classification dataset from ICML 2024 gave us a strong academic foundation with broad product category coverage.
- Synthetic data: We generated additional training examples to fill gaps in underrepresented classes and product categories, improving balance across all four classification labels.
- Manually labeled proprietary data: Real product-query pairs from our own stores, labeled by hand. This is what grounds the model in actual shopping behavior — the kind of messy, ambiguous queries real customers type, not clean academic examples.
The public data gave us scale. The synthetic data gave us balance. The proprietary data gave us accuracy on the queries that actually matter.
| Detail | Value |
|---|---|
| Base model | DistilBERT-base-uncased (66M params) |
| Training data | Public (ECInstruct) + synthetic + manually labeled proprietary |
| Classes | 4 (Exact / Substitute / Complement / Irrelevant) |
| Optimizer | AdamW, lr=3e-5, linear warmup |
| Hardware | CPU only (Apple Silicon) — no GPU needed |
| Inference latency | ~35ms per classification |
The model runs entirely on CPU. No GPU infrastructure. No API keys. No per-query cost.
The Benchmark: 7 Frontier LLMs, 400 Test Samples
We ran a rigorous head-to-head comparison against 7 of the most capable LLMs available today, across two test splits:
- In-Distribution (IND): 200 samples from the same data domain as training
- Out-of-Distribution (OOD): 200 samples from unseen product categories
All LLMs were evaluated zero-shot — given only the classification rubric (definitions of each class) with no examples. This is the fairest comparison: our model learned from training data, the LLMs had to reason from definitions alone.
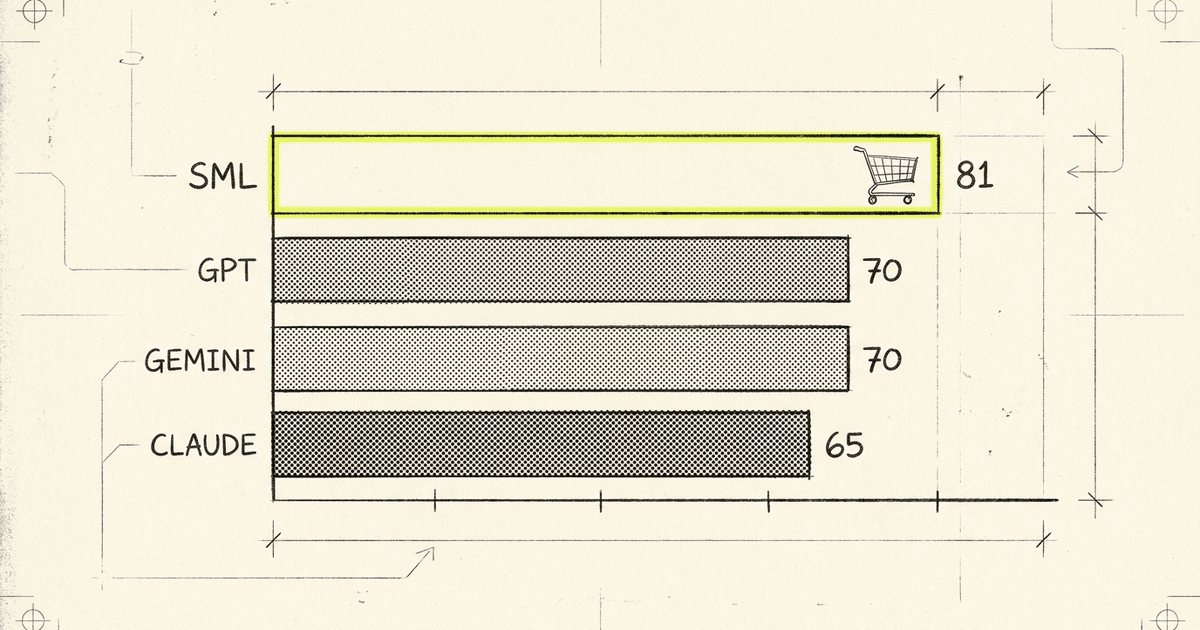
Results: In-Distribution Test
| Model | Accuracy | Latency | Cost per 1K queries |
|---|---|---|---|
| Chatcast DistilBERT | 81.0% | 37ms | $0.00 |
| Gemini 2.5 Pro | 70.0% | 2,285ms | $0.24 |
| GPT-4o | 69.5% | 803ms | $0.48 |
| Gemini 2.5 Flash Lite | 69.5% | 716ms | $0.02 |
| Claude Haiku 4.5 | 68.0% | 804ms | $0.23 |
| Claude Opus 4.5 | 67.0% | 1,516ms | $3.44 |
| GPT-4o-mini | 66.0% | 807ms | $0.03 |
| Claude Sonnet 4.5 | 65.0% | 1,212ms | $0.68 |
Results: Out-of-Distribution Test
| Model | Accuracy | Latency | Cost per 1K queries |
|---|---|---|---|
| Chatcast DistilBERT | 80.5% | 34ms | $0.00 |
| Gemini 2.5 Pro | 72.5% | 2,167ms | $0.24 |
| Claude Haiku 4.5 | 68.5% | 813ms | $0.23 |
| GPT-4o | 67.5% | 710ms | $0.48 |
| Claude Opus 4.5 | 64.5% | 1,701ms | $3.50 |
| Gemini 2.5 Flash Lite | 64.5% | 625ms | $0.02 |
| Claude Sonnet 4.5 | 62.5% | 1,239ms | $0.69 |
| GPT-4o-mini | 64.0% | 659ms | $0.03 |
Our 66M-parameter model outperformed every frontier LLM — including models with 1,000x more parameters.
What the Numbers Mean
1. Accuracy: +11 points over the best frontier LLM
On in-distribution data, our model hit 81.0% accuracy — 11 points ahead of the best-performing LLM (Gemini 2.5 Pro at 70.0%). On out-of-distribution data — product categories the model never saw during training — it still held at 80.5%, 8 points clear of the field. The gap held on harder data.
2. Latency: 20x faster
At 35ms average inference, our classifier returns a result before an LLM API call even completes its TLS handshake. For a real-time shopping assistant where every interaction involves multiple product relevance checks, this is the difference between a snappy experience and a loading spinner.
3. Cost: Literally free
Zero API cost. The model runs on the same CPU that serves the application. At 100K queries/day, the LLM alternatives would cost between $2–$350/day depending on the model. Ours costs nothing incremental.
4. Generalization holds
The OOD results are the real story. Our model dropped only 0.5 percentage points (81.0% → 80.5%) when classifying products from unseen categories. Most LLMs dropped 2–5 points. The fine-tuning didn't just memorize — it learned the structure of product-query relevance.
Per-Class Breakdown
Where our model really shines is on exact matches — the highest-stakes classification:
| Class | Description | IND Accuracy | OOD Accuracy |
|---|---|---|---|
| Exact Match | Product satisfies all query specs | 93.7% | 91.1% |
| Substitute | Functional alternative | 59.2% | 71.8% |
| Complement | Works in combination | 0.0%* | 20.0%* |
| Irrelevant | Not relevant to query | 65.2% | 42.9% |
*Complement class had only 2–5 test samples — not statistically meaningful.
93.7% accuracy on exact matches means that when our model says "this is the right product," it's almost always correct. That's the classification that drives conversions.
Why Small Models Win on Narrow Tasks
This isn't a knock on LLMs — we use frontier models extensively for the conversational layer of our shopping assistant. But classification is a different problem than generation.
LLMs are optimized to be general. They can write poetry, debug code, and analyze legal documents. That generality is a tax when all you need is a 4-way classification on structured e-commerce data. A fine-tuned small model:
- Learns the decision boundary directly from labeled data, instead of reasoning about it from a text rubric
- Has no prompt sensitivity — no fragile prompt engineering that breaks when you rephrase
- Runs deterministically at inference time — same input always produces the same output
- Scales horizontally with no rate limits, quotas, or API deprecation risk
The Takeaway for E-Commerce Builders
If you're building AI-powered commerce tools and routing every decision through an LLM API, you're likely paying more and getting less on classification tasks. The playbook:
- Use LLMs for what they're great at: natural language understanding, conversation, creative recommendations
- Use fine-tuned small models for what they're great at: fast, cheap, accurate classification on well-defined tasks
- Benchmark before you assume: "bigger model = better" is not a law of nature — it's a hypothesis you should test
At Chatcast, this classifier is one piece of a larger system that combines fine-tuned models with frontier LLMs to deliver the best possible shopping experience. Each component does what it's best at.
The public portion of our training data uses the ECInstruct dataset from NingLab/ECInstruct, introduced at ICML 2024.